If You Are Machine Learning Engineer, Data Scientist and Big Data analyst Than you should know about this tool


Table of contents
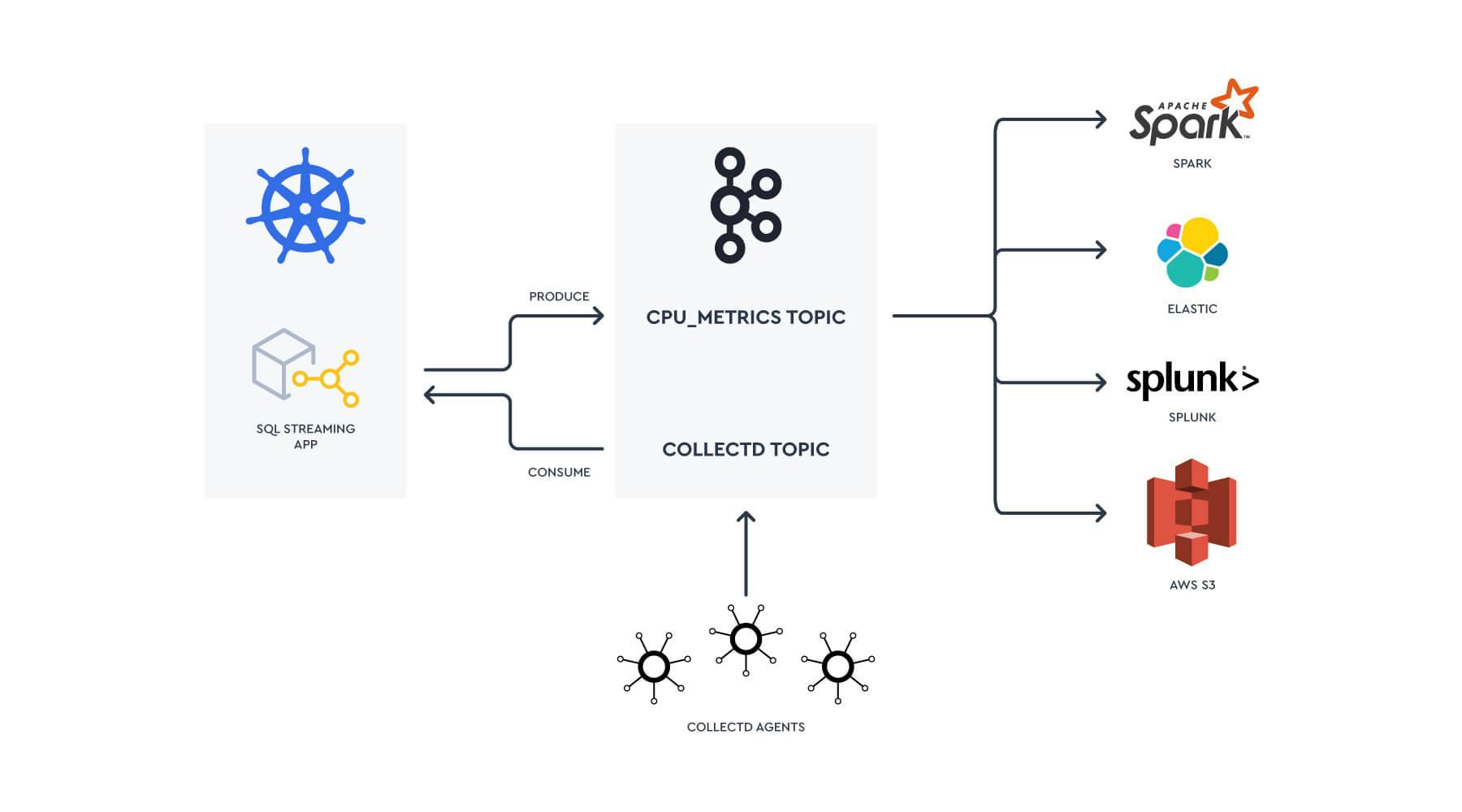
#kafka So the tool is kafka Apache Kafka is a distributed streaming system used for event stream processing, real-time data pipelines, and stream processing at scale. Apache Kafka consists of a storage layer and a compute layer that combines efficient, real-time data ingestion, streaming data pipelines, and storage across distributed systems. In short, this enables simplified, data streaming between Kafka and external systems, so you can easily manage real-time data and scale within any type of infrastructure.
What is kafka used for?
Apache Kafka is the most popular data streaming system for developers and architects alike. It provides a powerful event streaming platform complete with 4 APIs: Producer, Consumer, Streams, and Connect.
Often, developers will begin with a single use case. This could be using Kafka as a message buffer to protect a legacy database that can’t keep up with today’s workloads, or using Kafka Connect to sync your database with an accompanying search indexing engine, to process real-time streams of data with the Streams API, aggregating data right back to your application.
In short, Kafka unlocks powerful, event-driven programming for virtually any infrastructure. Build real-time, data-driven apps and make complex back-end systems simple. Process, store, and connect your apps and systems with real-time data.
- Stream Processing
- Data Integration
- Event-Driven Microservices
- Streaming Analytics
- Data Streaming
- Streaming ETL Pipelines
- Messaging Queues
- Publish-Subscribe